James-Stein estimator
Intuition behind Stein estimator
Brown and Zhao (2012) works through the geometric intuition behind the estimator.
It requires that we change our basis for \(\R^K\) from the standard basis to a basis in which one vector is pointed in the direction of \(\boldsymbol{\theta}\), and the rest are orthogonal to that direction.
The way we would do that is to do something like:
X <- theta + rnorm(10)
X_in_new_basis <- t(basis_mat) %*% X
red_X <- c(X_in_new_basis[1], sqrt(sum(tail(X_in_new_basis^2,-1))))
plot(red_theta[1],0, xlim = c(0,5), ylim = c(0,5),
xlab = "Theta axis", ylab = "Residual axis",
col = "red", pch = 19)
Xs <- sweep(matrix(rnorm(1e4), 10, 1e3), 1, theta, FUN = "+")
trans_Xs <- t(basis_mat) %*% Xs
trans_Xs_red <- cbind(trans_Xs[1,], sqrt(colSums(trans_Xs[2:10,]^2)))
points(trans_Xs_red[,1], trans_Xs_red[,2],pch = 19, col = scales::alpha("black",0.6))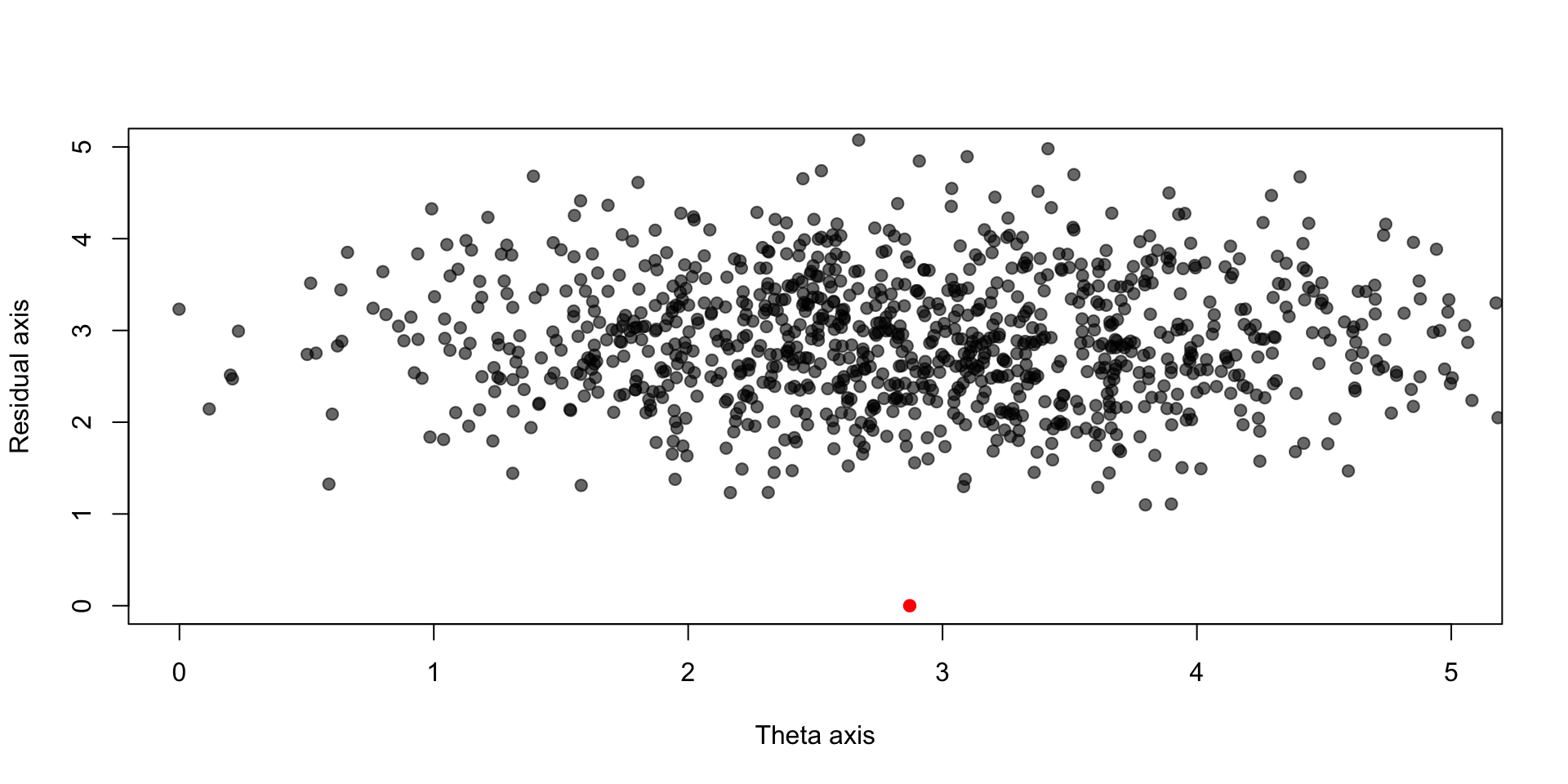
The point cloud is shifted above the true theta; this shift gets worse as dimension of \(\boldsymbol{\theta}\) increases
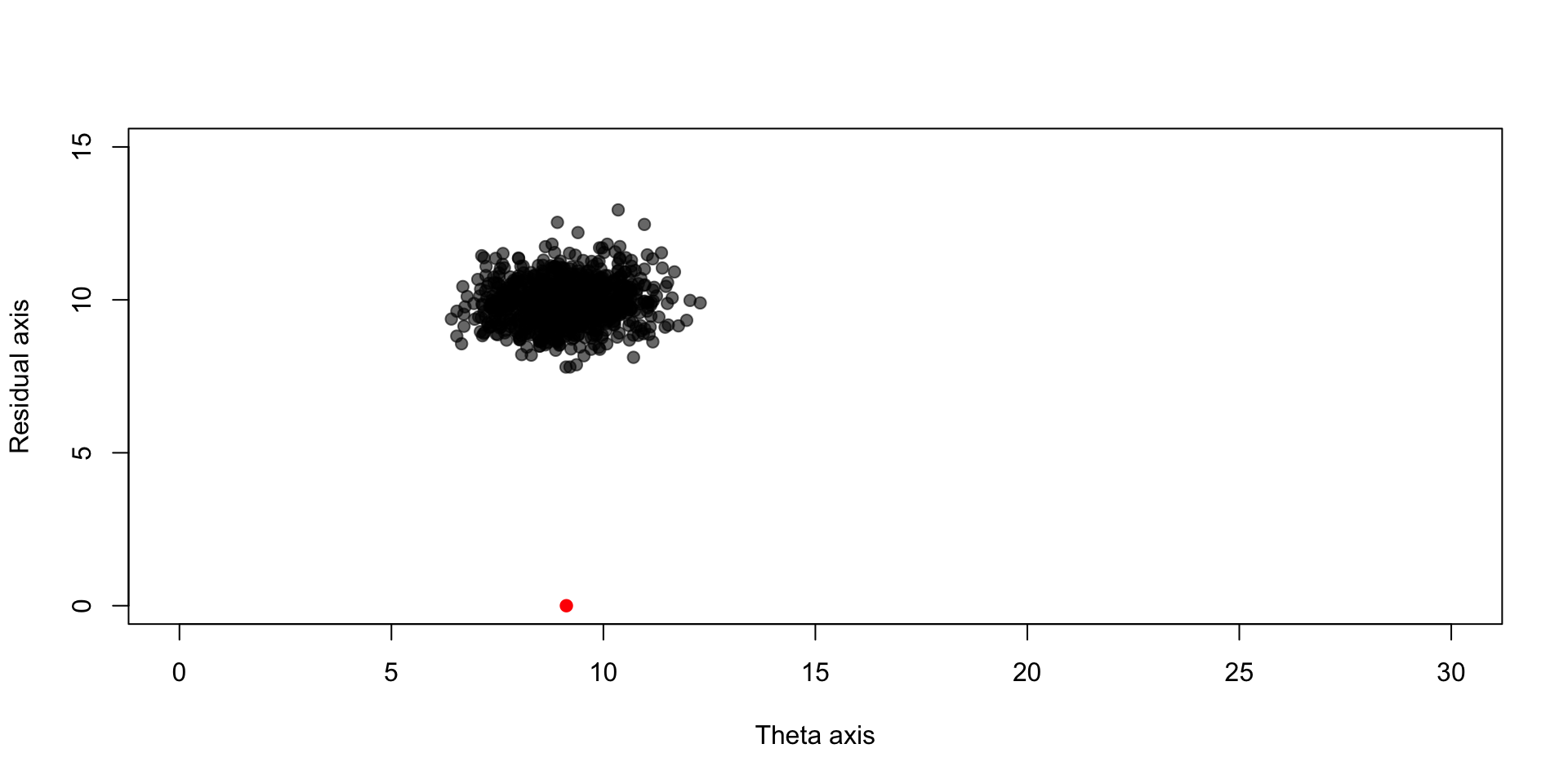
James-Stein estimator
Ideally we would like to shrink our estimators toward \(\boldsymbol{\theta}\), but in the absence of knowledge of this point, we can shrink toward the origin:
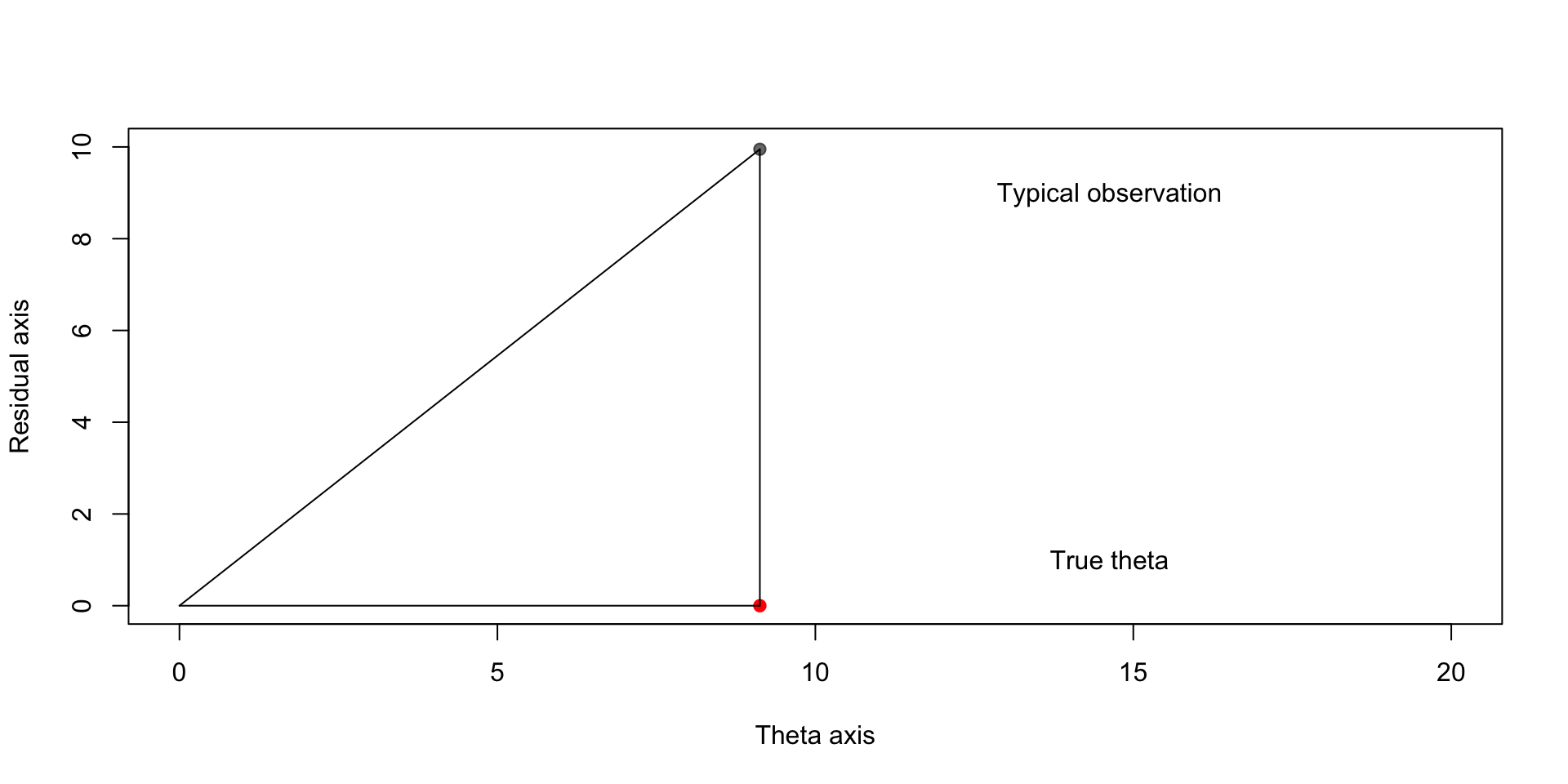
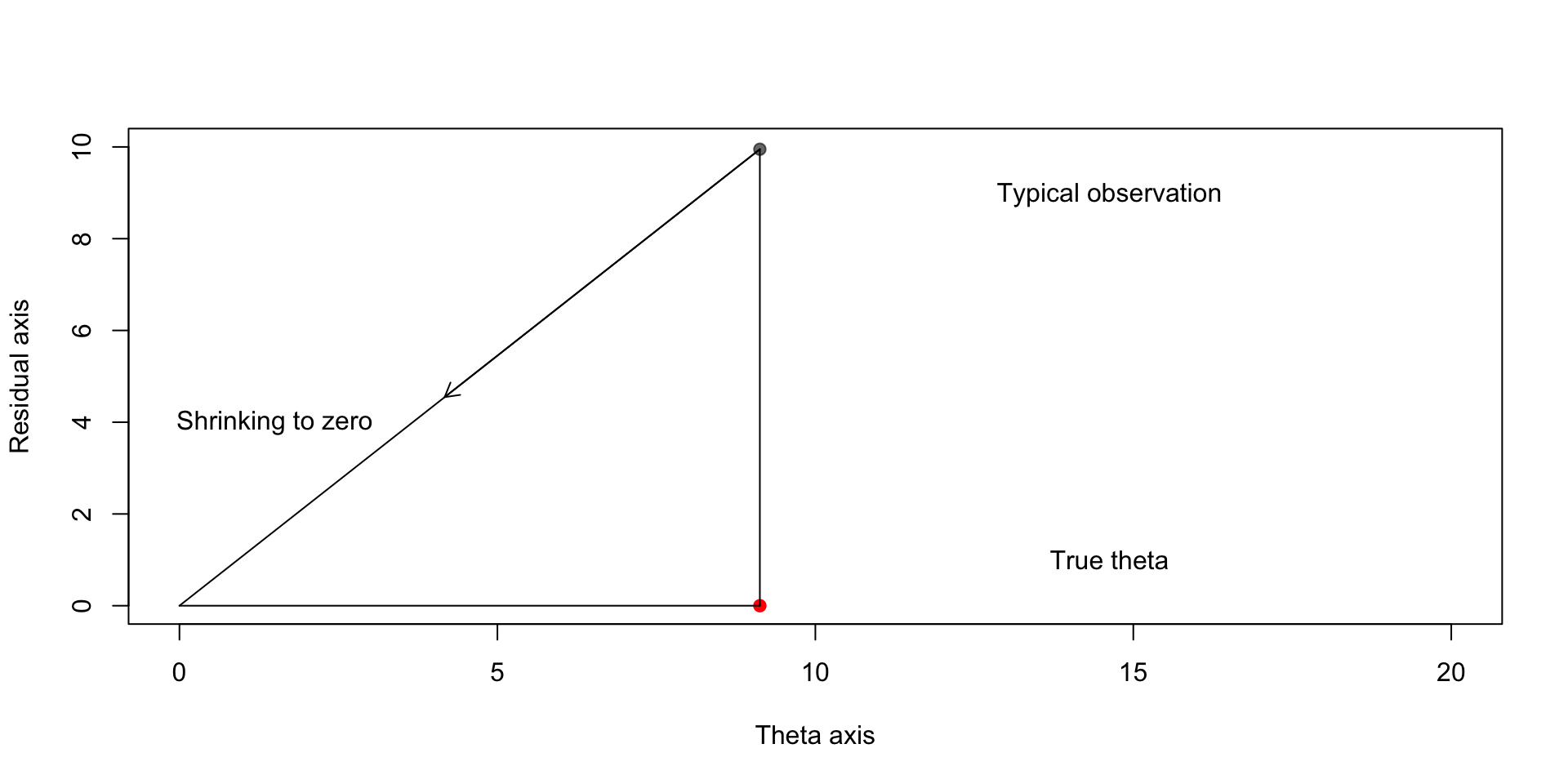
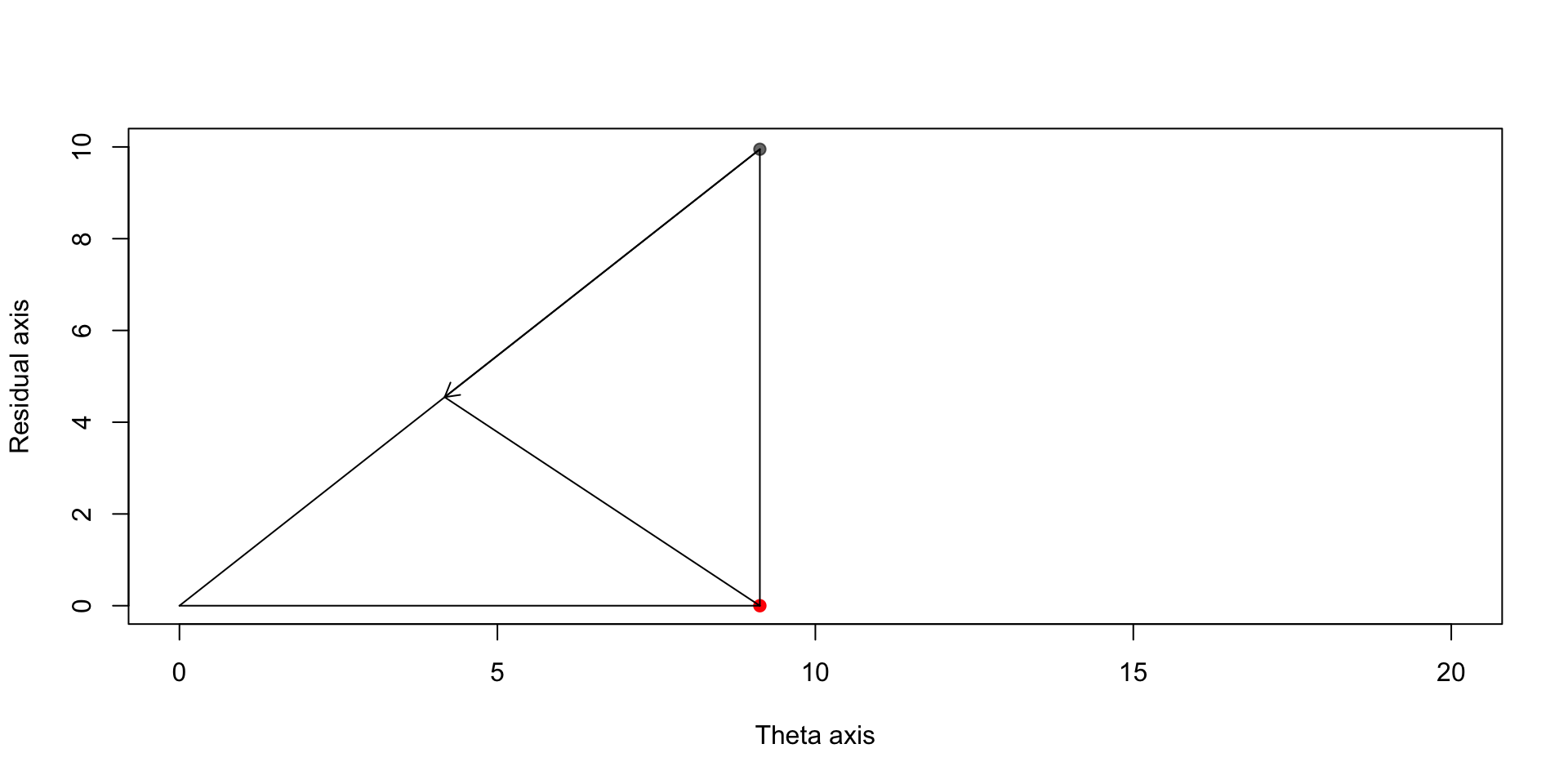
Finding the optimal shrinkage
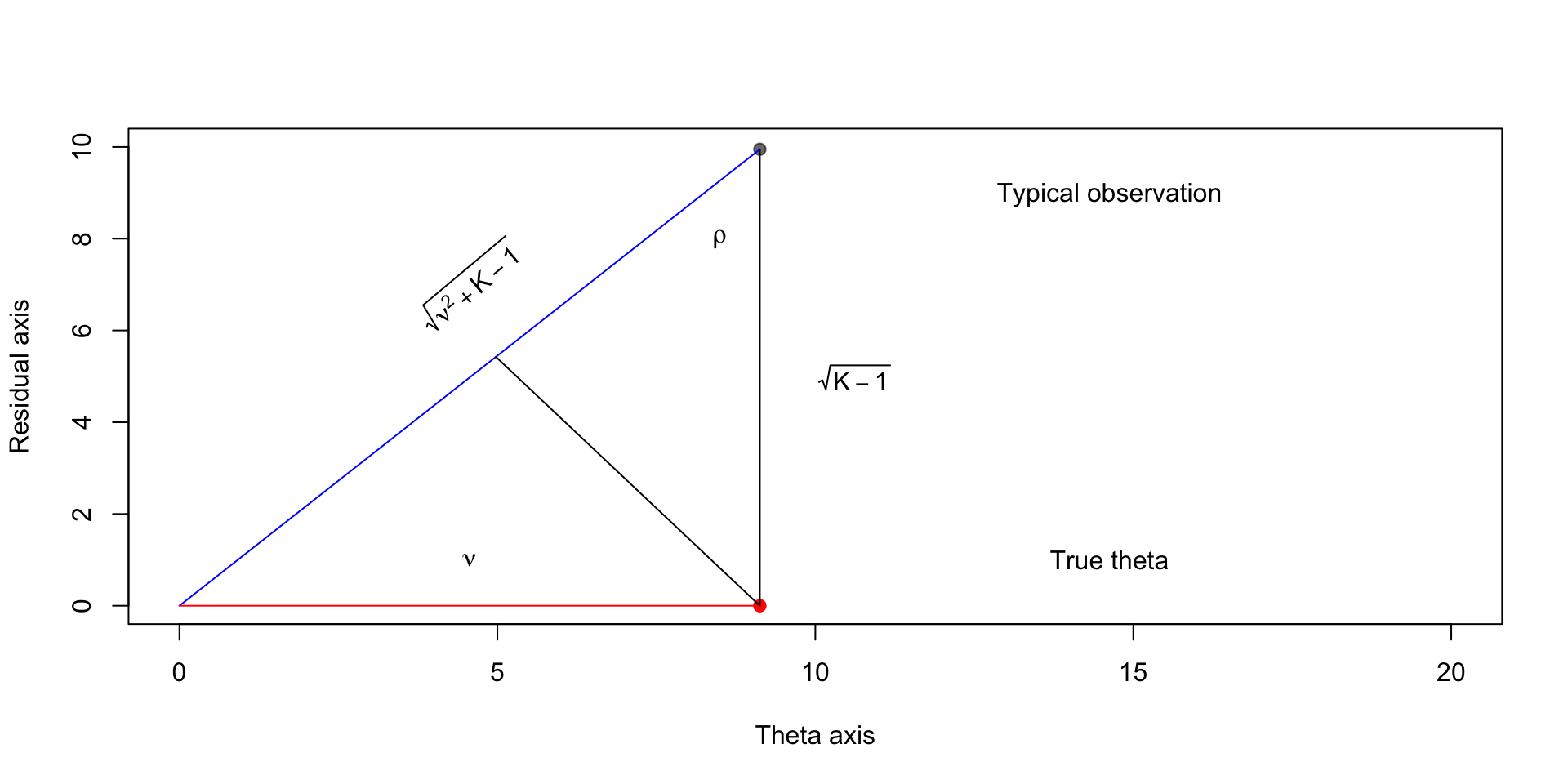
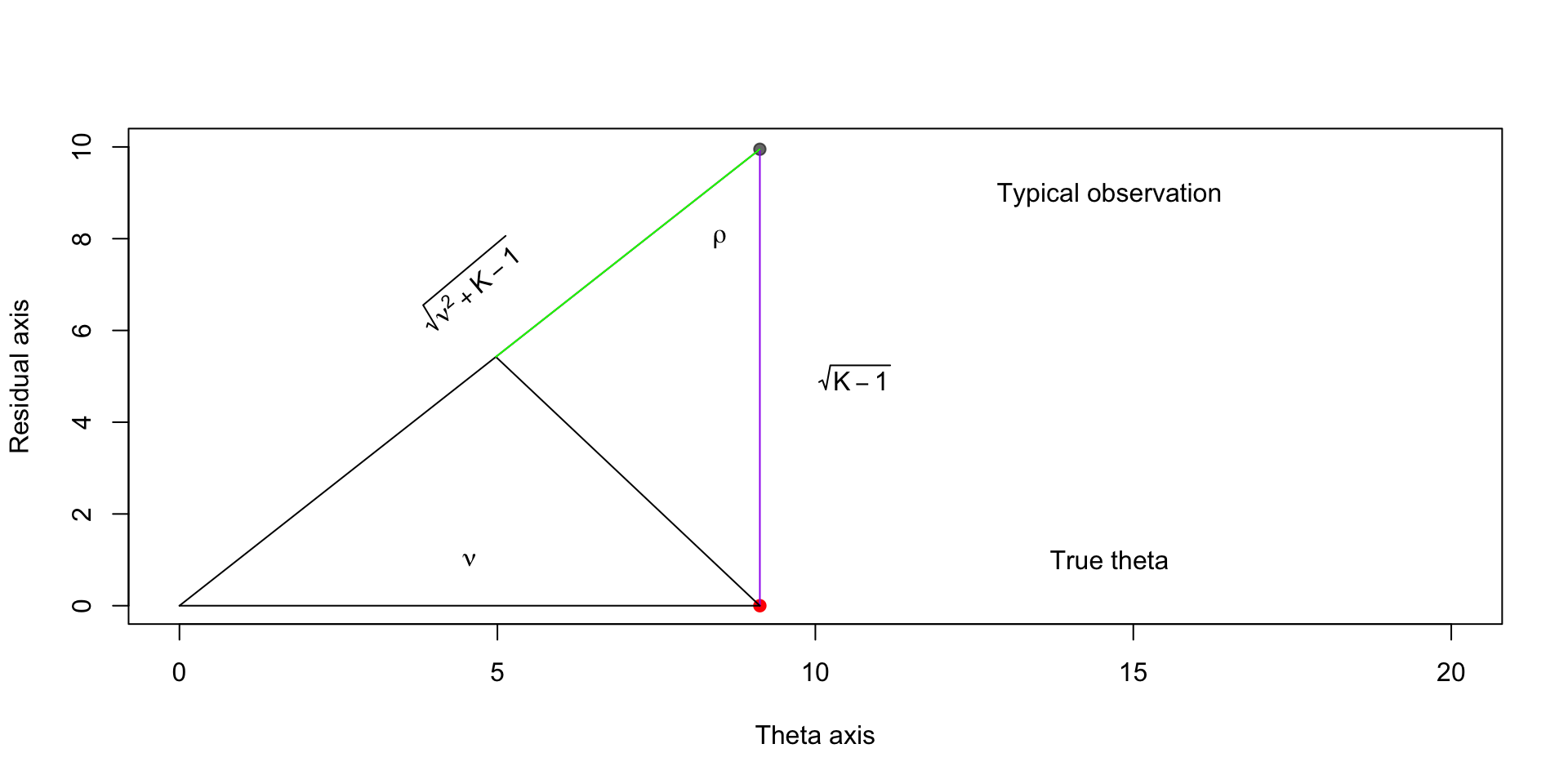
\[ \begin{aligned} \sin \rho & = \frac{\textcolor{red}{\nu}}{\textcolor{blue}{\sqrt{\nu^2 + K - 1}}} \end{aligned} \]
\[ \begin{aligned} \sin \rho & = \frac{\textcolor{green}{y}}{\textcolor{purple}{\sqrt{K - 1}}} \end{aligned} \]
Implies that \(y = \sqrt{K - 1} \frac{\nu}{\sqrt{\nu^2 + K - 1}}\)
Compare this to \(\sqrt{K-1}\), which is how far away the typical observation is
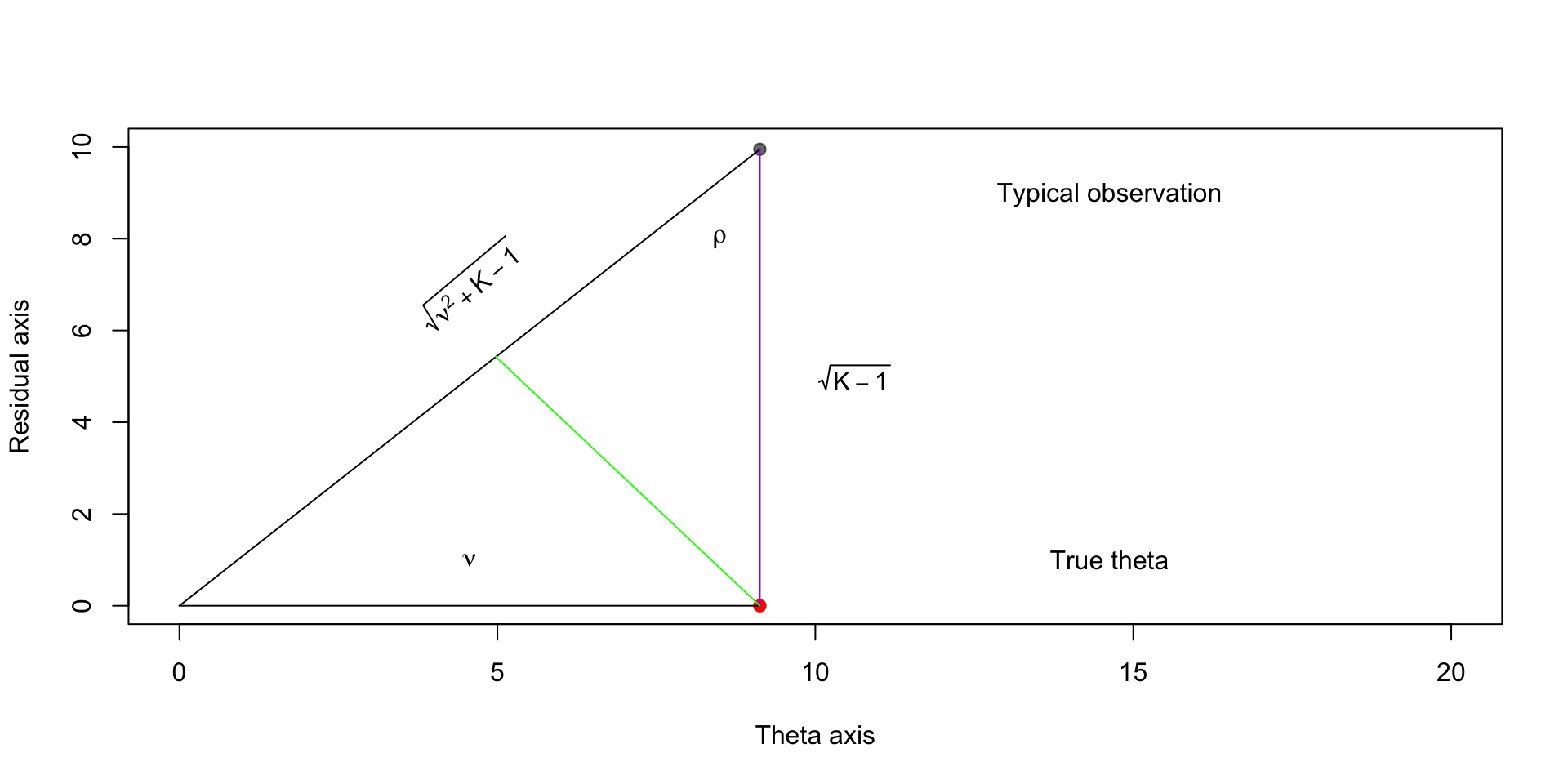
Finding the optimal estimator
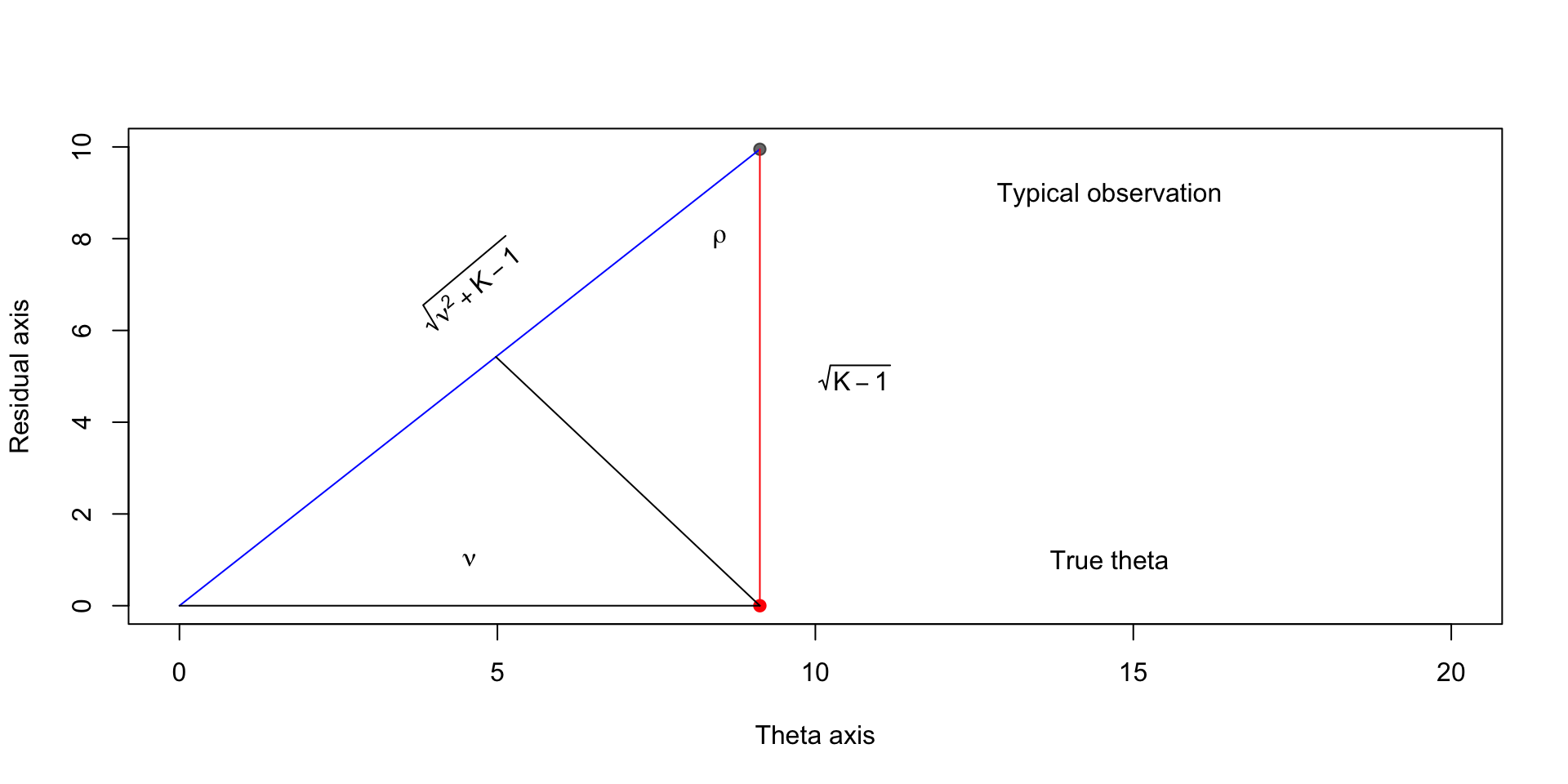
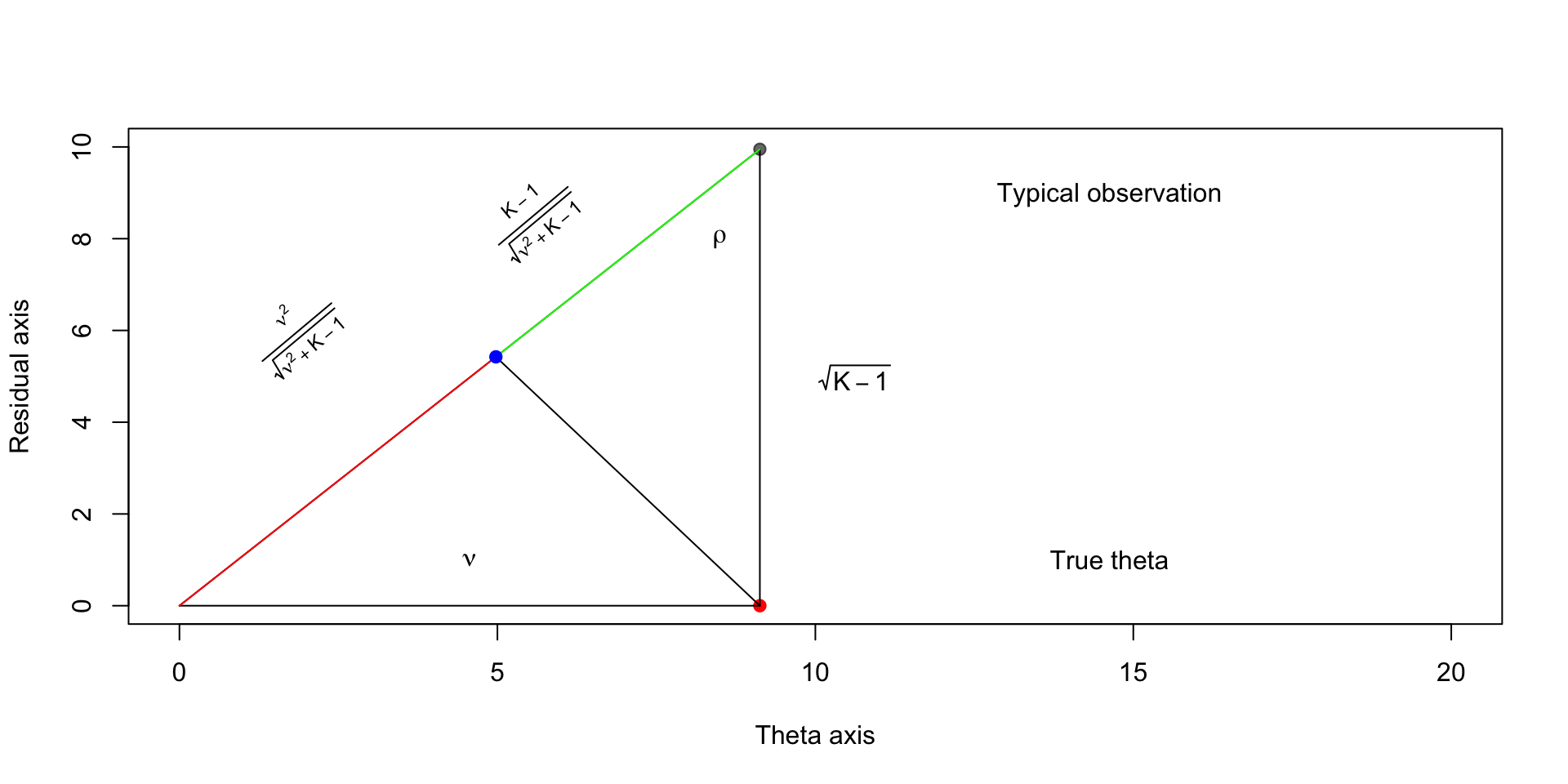
\[ \begin{aligned} \cos \rho & = \frac{\textcolor{red}{\sqrt{K-1}}}{\textcolor{blue}{\sqrt{\nu^2 + K - 1}}} \end{aligned} \]
\[ \begin{aligned} \cos \rho & = \frac{\textcolor{green}{y}}{\textcolor{purple}{\sqrt{K - 1}}} \end{aligned} \]
Implies that \(y = \frac{K - 1}{\sqrt{\nu^2 + K - 1}}\).
This means that we shrink the point \((\nu, \sqrt{K-1})\) to the origin by the amount \(\lp 1 - \frac{K - 1}{\nu^2 + K - 1}\rp\)
Then the estimator in this new basis is \[ \lp 1 - \frac{K - 1}{\nu^2 + K - 1}\rp\begin{bmatrix} \nu \\ \sqrt{K - 1} \end{bmatrix} \]
Plots of \(\kappa_i\) for different shrinkage priors
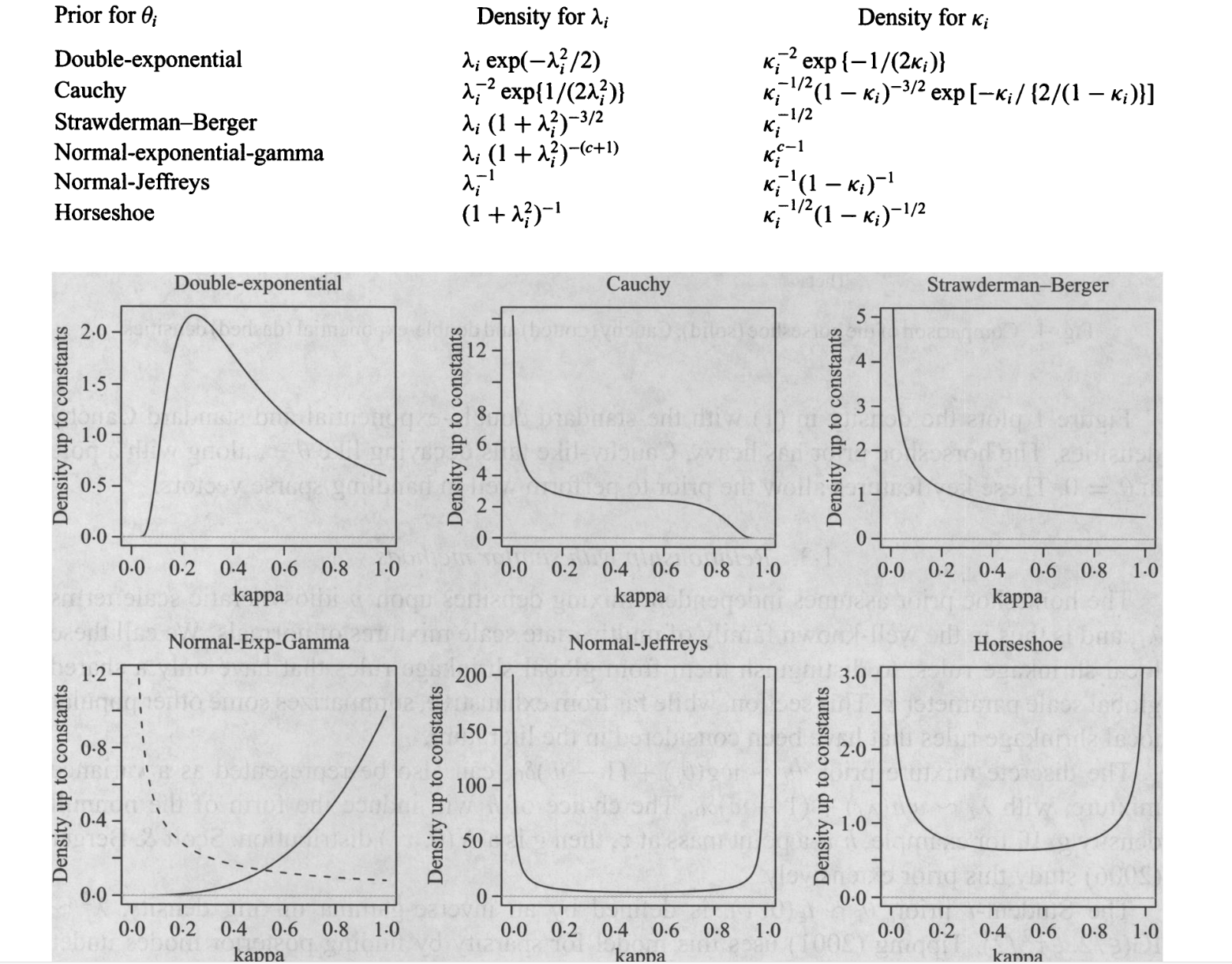
Shrinkage factors